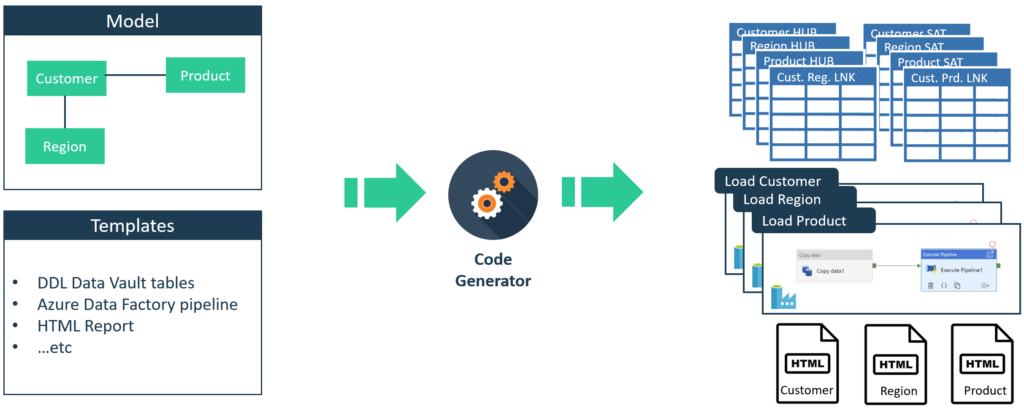
Een model gedreven aanpak kan helpen in het efficiënter ontwikkelen van een datawarehouse. Doordat er minder software met de hand wordt geschreven kan nieuwe functionaliteit sneller worden opgeleverd.
Door de functionaliteit in een model te definiëren in plaats van in een specifieke techniek is de oplossing beter te onderhouden en eenvoudiger te migreren naar een andere technologie.
Meer weten over dit onderwerp en de mogelijkheden voor uw organisatie? Lees de rest van dit artikel of neem direct contact op met CrossBreeze om de mogelijkheden te bespreken.
Voor wie is dit artikel
Dit artikel is geschreven voor iedereen die betrokken is bij de ontwikkeling van een data oplossing zoals een datawarehouse en die een of meer van onderstaande problemen herkent:
- Ontwikkelen van nieuwe functionaliteit in het datawarehouse is tijdrovend, het kost veel tijd om een nieuwe feature van begin tot eind gerealiseerd en opgeleverd te krijgen.
- De kwaliteit van het datawarehouse is onvoldoende maar het is teveel werk om alle verouderde delen van de software te verbeteren.
- Het datawarehouse maakt gebruik van verouderde technologie maar migratie is enorm veel werk.
Bekende problemen in een datawarehouse
Of je nu in een meer traditionele omgeving zit waarbij het datawarehouse ontwikkeld wordt op een databaseplatform als SQL Server of Oracle met ETL producten als SQL Server Integration Services en Informatica PowerCenter of in een modernere stack bezig bent met producten zoals Azure Synapse, Snowflake en Databricks;
Bij de realisatie van de benodigde datastructuren en (met name) datastromen komt doorgaans veel handmatig ontwikkelwerk kijken. Het feit dat er veel software met de hand wordt ontwikkeld heeft een aantal nadelige gevolgen:
De doorlooptijd voor nieuwe functionaliteit is lang
Een nieuwe feature moet vaak in verschillende onderdelen van het datawarehouse worden doorgevoerd voordat de eindgebruiker er baat bij heeft. Denk bijvoorbeeld aan een nieuw dashboard waarvoor gegevens nodig zijn die nog niet in het datawarehouse worden ingelezen.
Bij de implementatie lopen functionele en technische aspecten door elkaar. Denk bijvoorbeeld aan de implementatie van een bepaalde berekening die nodig is om het gevraagde resultaat op te leveren (functioneel) in combinatie met het historisch wegschrijven van het resultaat in een datavault model (technisch). Deze vermenging van functionele en technische aspecten maakt het ontwikkelen onnodig complex en stelt teams onvoldoende in staat om de afzonderlijke aspecten bij de juiste teamleden te beleggen.
Ook het testen en opleveren van de gerealiseerde functionaliteit kost tijd, zeker als hier veel handwerk in zit.
Het datawarehouse is geëvolueerd en daardoor moeilijk te beheren
Wanneer er meerdere ontwikkelaars aan het datawarehouse ontwikkelen is de kans groot dat er verschillen ontstaan in de implementatie op basis van persoonlijke voorkeuren. Daarnaast zorgt voortschrijdend inzicht er voor dat de patronen en richtlijnen die worden gehanteerd in de loop van de tijd veranderen. Vaak worden deze nieuwe inzichten echter alleen toegepast op nieuw te ontwikkelen functionaliteit en niet met terugwerkende kracht op de bestaande onderdelen. Hierdoor ontstaat een heterogeen product.
Er is sprake van verouderde technologie
Een van de grote waarden van een datawarehouse is dat het veel historische data bevat. Doorgaans is het dan ook de bedoeling dat een datawarehouse vele jaren gebruikt kan worden in een organisatie. De technologische ontwikkelingen staan echter niet stil waardoor het niet ongewoon is dat, ondanks dat de oplossing functioneel nog wel voldoet, op technisch vlak een migratie nodig is om bij te blijven. Wanneer alle functionaliteit handmatig is ontwikkeld in een bepaald platform zit de functionaliteit van het datawarehouse als het ware opgesloten in deze techniek. Migratie betekent vaak dat grote delen opnieuw met de hand worden ontwikkeld in een modernere omgeving ondanks dat de functionele wensen grotendeels gelijk zijn gebleven.
Uitgangspunten Model Driven Data Engineering
Een model gedreven aanpak helpt om de hierboven genoemde problemen te adresseren. Uitgangspunten van Model Driven Data Engineering zijn:
Functionaliteit vastleggen in een model, niet in een technologie
In plaats van het vermengen van de technische en functionele logica wordt er een strikte scheiding gehanteerd: functionele logica wordt vastgelegd in een model. Technische logica in patronen. De functionele logica wordt daarbij zoveel mogelijk technologie onafhankelijk gedefinieerd.
Onder functionele logica verstaan we in deze context:
- De logische structuur van de lagen van het datawarehouse (entiteiten met attributen en relaties)
- Data lineage, ofwel het vastleggen welke gegevensstromen nodig zijn door middel van het “mappen” van entiteiten en attributen in een bronmodel op entiteiten en attributen in een doelmodel
- Business rules of functionele transformaties (afleidingen, berekeningen,….)
Technologie vertalen in templates
Om op basis van de informatie in het model tot een implementatie te komen worden templates (patronen) ontwikkeld in de beoogde doeltechnologie. Een template kan bijvoorbeeld zijn:
- Een SQL script voor het aanmaken van een tabel
- Een Azure Data Factory job voor het laden van data
- Een testscenario om een bepaalde businessrule te testen
Genereren in plaats van handmatig ontwikkelen
Op basis van het model en de templates kan de implementatie worden gegenereerd. Door gebruik te maken van een code generator worden de templates en het model gecombineerd, waarbij informatie uit het model in de templates wordt ingevuld om zo de uiteindelijke software te verkrijgen.
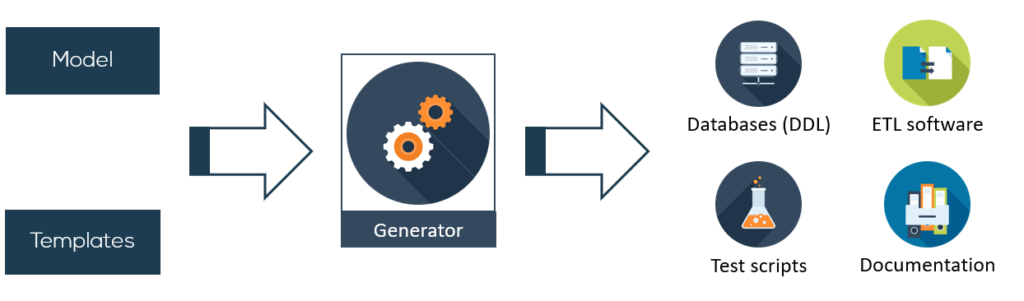
Voordelen Model Driven Data Engineering
Minder handwerk = sneller opleveren
Bij model gedreven ontwikkelen wordt er minder code met de hand geschreven. Elk type patroon wordt maar één keer gecodeerd in een template in plaats van voor elke verschijning.
Een nieuwe entiteit toevoegen aan het datawarehouse betekent dus niet dat deze handmatig overal hoeft te worden geïmplementeerd; Door de entiteit in het model te definiëren en opnieuw de code te genereren wordt deze in alle onderdelen van het datawarehouse verwerkt.
Bijkomend voordeel is ook dat je zeker weet dat de implementatie in alle onderdelen consistent is, er kunnen geen onbedoelde verschillen zijn ontstaan als gevolg van handmatig werk.
Minder code = grotere beheersbaarheid
Met model gedreven ontwikkelen is de handmatig te onderhouden codebase veel kleiner geworden. In plaats van alle afzonderlijke onderdelen is er een veel kleinere set van code templates die men onderhoudt.
Indien een template als gevolg van nieuwe inzichten wordt gewijzigd kan het volledige systeem volgens de nieuwe inzichten worden gegenereerd. Het systeem blijft daardoor veel eenduidiger in opzet en daarmee eenvoudiger.
Minder code = sneller migreren
Bij de overgang naar een nieuwe technologie ligt de focus vooral op het creëren van nieuwe templates. Omdat het model grotendeels technologie onafhankelijk is, zal hier niet of nauwelijks iets gewijzigd hoeven te worden wanneer men wil migreren naar een andere technologie.
Aandachtspunten Model Driven Data Engineering
Naast de hierboven genoemde voordelen zijn er ook aandachtspunten die van belang zijn
Abstract vs concreet
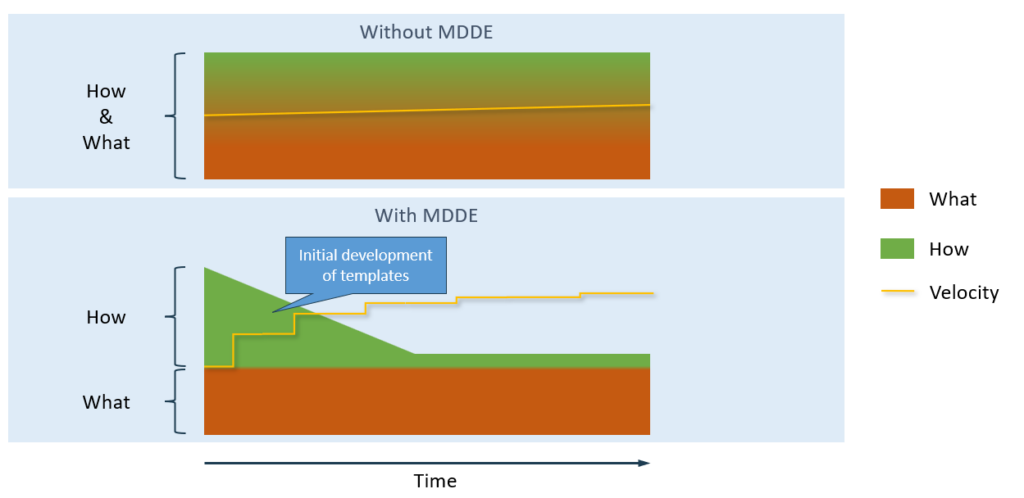
Bij de implementatie van model gedreven implementatie is het zaak om met een abstractere bril te kijken naar de benodigde implementatie. In plaats van het direct implementeren van verschillende use cases is het de kunst om op basis van de overeenkomsten en de verschillen te komen tot een afweging t.a.v. de benodigde templates.
Doorgaans zien we bij een model gedreven aanpak regelmatig dat in het beginstadium de velocity wat lager ligt dan bij de traditionele werkwijze, maar zodra de basis aan tools en templates voorhanden is wordt dit meer dan goedgemaakt.
Data migratie
Evenals bij een handmatig ontwikkeld datawarehouse is ook bij een omgeving die op model gedreven wijze tot stand komt data migratie een aandachtspunt: Dat het mogelijk is om alle code opnieuw te genereren volgens laatste inzichten wil natuurlijk niet zeggen dat de bestaande data automatisch is getransformeerd naar de nieuwe structuur.
Vaak helpt een model gedreven aanpak wel om ook op dit vlak het proces te vereenvoudigen/automatiseren omdat vanuit het model veel metadata beschikbaar kan worden gemaakt die weer gebruikt kan worden om data migratie te ondersteunen en delen hiervan te genereren.
Snelheid vs technische ontkoppeling
In de praktijk is er altijd een afweging te maken tussen de mate waarin het model echt technologie onafhankelijk is of dat er toch op bepaalde vlakken techniek wordt gebruikt, bijvoorbeeld kleine stukjes (ANSI) SQL om een transformatie te definiëren.
Ook is er een keuze tussen in hoeverre alles in het model wordt gedefinieerd of dat er een andere balans wordt gekozen, bijvoorbeeld om van transformaties de signature in het model te definiëren en de implementatie wel in een specifieke technologie.
Aspecten die een rol spelen bij deze afwegingen zijn:
- Ontwikkelsnelheid (is modelleren veel sneller/langzamer dan coderen)
- Lineage requirements (Tot welk niveau dient men lineage te kunnen aantonen)
- Migratie risico (hoe technologie specifiek is een bepaalde implementatie, denk aan ANSI SQL vs platform specifiek zoals T-SQL of PL-SQL)
Homegrown vs Open source
In diverse organisaties worden eigen tools en generatoren ontwikkeld om model gedreven te werken. Ondanks dat dit een flinke verbetering oplevert ten opzichte van alles handmatig realiseren leidt dit ook vaak tot een enorme afhankelijkheid van één of enkele (al dan niet externe) medewerkers die deze tools ontwikkeld hebben.
Regelmatig vertrekken medewerkers naar andere werkgevers om daar een vergelijkbare oplossing te implementeren en blijft de eerste partij achter met een product wat moeilijk onderhoudbaar is door anderen.
Voor de meeste organisaties is het model gedreven ontwikkelen van hun data warehouse geen concurrentiegevoelige activiteit. Er is dus veel te winnen door op dit vlak juist samenwerking met andere bedrijven te zoeken en het delen van elkaars initiatieven te stimuleren.
Door eigen ontwikkelde tools open source te maken en ook gebruik te maken van bestaande open source componenten verbetert de beheersbaarheid en levensduur van dit soort oplossingen.
Model Driven Data Engineering in uw organisatie?
Is uw organisatie (te) veel tijd kwijt aan het ontwikkelen van uw data warehouse, of voorziet u in de nabije toekomst een migratie in verband met verouderde technologie of een verschuiving van on premise naar cloud?
Wij laten u graag zien hoe Model Driven Data Engineering in uw specifieke situatie kan helpen om de ontwikkeling aanzienlijk te versnellen.
Ook wanneer u al een intern ontwikkelde generator of metadata gedreven tool gebruikt die lastig te onderhouden blijkt kunnen wij ondersteunen met een passende oplossing.
Neem contact op met CrossBreeze om te bespreken hoe wij uw organisatie kunnen ondersteunen.




