A model driven approach increases efficiency in datawarehouse developement. Since less software is written by hand, new features can be delivered faster
Specifying functionality in a model instead of in a specific technology increases maintainability and reduces migration effort if a new technology is to be used.
Want to know how your organization could benefit from our approach? Read the remainder of this article or contact us directly to discuss options.
Intended audience for this article
This article is written for anyone involved in the development of a data solution such as a data warehouse and who recognizes one or more of the following problems:
- Developing new functionality in the data warehouse is time-consuming, it takes a lot of time to have a new feature implemented and delivered from start to finish.
- The quality of the data warehouse software is insufficient, but it is too much work to improve all outdated parts of the software.
- The data warehouse uses outdated technology, but migration is a huge amount of work.
Common issues in datawarehouse projects
Whether you are in a more traditional environment where the data warehouse is developed on a database platform such as SQL Server or Oracle with ETL products such as SQL Server Integration Services and Informatica PowerCenter or you are working in a more modern stack with products such as Azure Synapse, Snowflake and Databricks;
The realization of the required data structures and (particularly) data flows usually involves a lot of manual development work. The fact that a lot of software is developed by hand has a number of negative consequences:
Long lead times for new features
A new feature often needs to be implemented in different layers of the data warehouse before the end user benefits from it. For example, consider a new dashboard that requires data that is not yet read into the data warehouse.
Functional and technical aspects are intertwined during implementation. For example, consider the implementation of a certain calculation that is necessary to deliver the requested result (functional) in combination with the historical recording of that result in a data vault model (technical). This mix of functional and technical aspects makes development unnecessarily complex and does not enable teams to properly allocate the individual aspects to the right team members.
Testing and delivering the new features also takes time, especially if it involves a lot of manual work.
The datawarehouse has evolved over time, making it difficult to maintain
When multiple developers develop the data warehouse, chances are that differences will arise in the implementation based on personal preferences. In addition, new insights result in the changing of patterns and guidelines over time. However, these new insights are often only applied to newly developed functionality and not retroactively to the entire system. This leads to a heterogeneous system
Outdated technology
One of the great values of a data warehouse is that it contains a lot of historical data. Typically, the intention is that a data warehouse can be used in an organization for many years. However, technological developments keeps progressing over time so it is not unusual that, despite the fact that the system still fulfills the functional requirements, a technical migration is necessary in order to stay operational. When all functionality has been developed manually in a specific platform or technology, the functionality of the data warehouse is, as it were, locked up in this technology. Migration in these cases often means that large parts are redeveloped by hand in a more modern tech stack, even though the functional requirements have largely remained the same.
Key points Model Driven Data Engineering
A model-driven approach helps to address the problems mentioned above. Key points of Model Driven Data Engineering are:
Specify functionality in a model, not in a technology
Instead of mixing technical and functional logic, a strict separation is used: functional logic is specified in a model. Technical logic in templates. The functional logic is defined technology agnostic as much as possible.
By functional logic in this context we mean:
- The logical structure of the data warehouse layers (entities with attributes and relationships)
- Data lineage, or capturing which data flows are needed by “mapping” entities and attributes in a source model to entities and attributes in a target model
- Business rules or functional transformations (derivations, calculations,….)
Specify technical aspects in templates
To get to an implementation based on the information in the model, templates (patterns) are developed in the intended target technology. Examples of templates are:
- A create table SQL script
- An Azure Data Factory job for loading data
- A test scenario for a specific type of business rule
Generating code instead of manual development
The implementation can be generated based on the model and the templates. With the use of a code generator, the templates and the model are merged: contents of the model is fed into the templates to create the actual software.
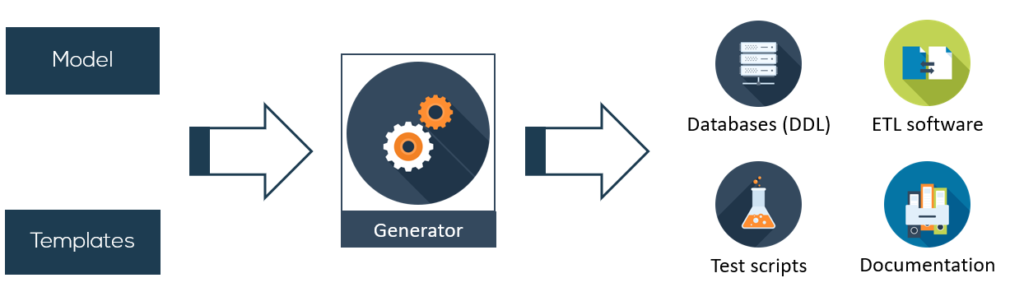
Benefits of Model Driven Data Engineering
Less manual labour = shorter time to market
With model-driven development, less code is written by hand. Each type of pattern is only implemented once in a template instead of for each occurrence.
Adding a new entity to the data warehouse does not mean manually implementing it in all layers; By defining the entity in the model and generating the code again, it is processed in all parts of the data warehouse.
An additional advantage is that you can be sure that the implementation is consistent in all parts, no unintentional differences can have arisen as a result of manual work.
Less code = better maintainability
With model-driven development, the code base that has to be maintained has become much smaller. Instead of all the individual components, there is only the set of code templates that are maintained.
If a template is changed as a result of new insights, the entire system can be generated according to the new insights. The system therefore remains much more uniform in design and therefore simpler.
Less code = faster migration
When transitioning to a new technology, the focus is mainly on creating new templates. Because the model is largely technology agnostic, little or no changes will need to be made here if you want to migrate to another technology.
Considerations for Model Driven Data Engineering
Apart from the benefits outlined in this article there are also considerations to take into account
Abstract vs Specific
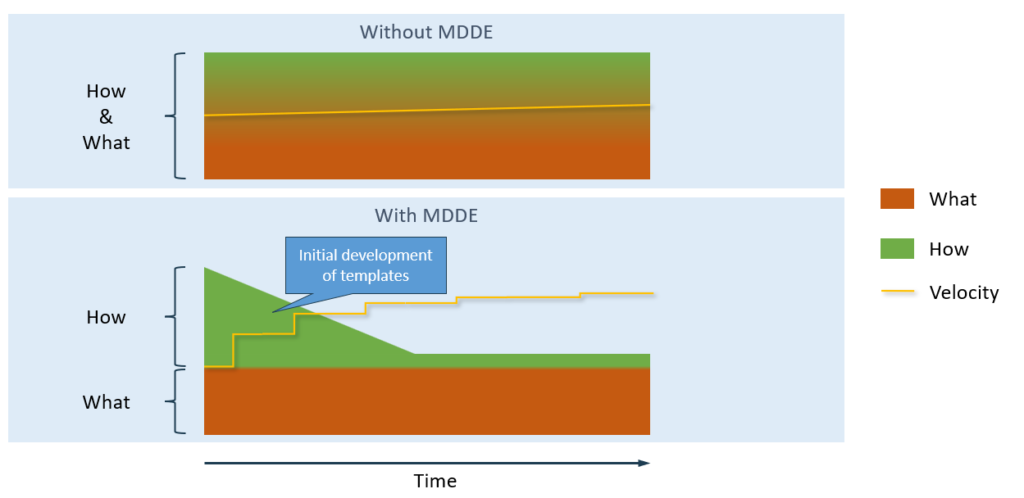
When implementing model-driven implementation, it is important to consider the required implementation from a more abstract perspective. Instead of directly implementing different features, the key is to make a decision regarding the required templates based on the similarities and differences of these features.
With a model-driven approach, we often see that the velocity is somewhat lower in the initial stages than with the traditional method, but once the basic tools and templates are set-up, this is more than made up for.
Data migration
As with a manually developed data warehouse, data migration is also a point of attention in an environment that is created using a model-driven approach: The fact that it is possible to regenerate all code according to the latest insights does not mean that the existing data has been automatically transformed into the new structure as well.
A model-driven approach however often helps to simplify/automate the data migration process because a lot of metadata is available from the models. This metadata can be used to support data migration and generate parts of it.
Development speed vs Technical decoupling
In practice there is always a trade-off to be made between the extent to which the model is truly technology agnostic and the effort that is needed to achieve this. There is an argument to be made for example, to allow certain parts of the model ,such as business rules, to be specified using small pieces of (ANSI) SQL.
There are also variations on the extent of what is defined in the model. For example: Some organizations opt to completely specify business rules in a model where others prefer to only model the signature and create the implementation in a specific technology.
Aspects that play a role in these considerations:
- Speed of development: modeling can be slower or faster then development depending on specific scenario characteristics.
- Lineage requirements (to what extent is lineage required)
- Migration risk (how technology specific is a particular implementation, think of ANSI SQL vs platform specific such as T-SQL or PL-SQL)
Homegrown vs Open source
Various organizations are developing their own tools and generators for their model-driven approach. Although this provides a significant improvement compared to implementing everything manually, it often leads to an enormous dependence on one or a few (external) employees who are capable of developing these tools.
Employees regularly leave for other employers to implement a similar solution and the first party is left with a product that is difficult for others to maintain.
For most organizations, Implementing the tools for a model-driven development approach is not a key activity There is therefore much to be gained by seeking cooperation with other companies in this area and encouraging the sharing of each other’s initiatives.
Making proprietary tools open source and also using existing open source components improves the manageability and lifespan of these types of solutions.
Model Driven Data Engineering in your organization?
Does your organization spend (too) much time developing your data warehouse, or do you foresee a migration in the near future due to outdated technology or a shift from on-premise to cloud?
Let us show you how Model Driven Data Engineering can help to significantly accelerate development in your specific situation.
Even if you are already using an internally developed generator or metadata-driven tool that proves difficult to maintain, we can support you with a suitable solution.
Contact CrossBreeze to discuss how we can support your organization.